Chapter 1 Lun 416B cell line (Smart-seq2)
1.1 Introduction
The Lun et al. (2017) dataset contains two 96-well plates of 416B cells (an immortalized mouse myeloid progenitor cell line), processed using the Smart-seq2 protocol (Picelli et al. 2014). A constant amount of spike-in RNA from the External RNA Controls Consortium (ERCC) was also added to each cell’s lysate prior to library preparation. High-throughput sequencing was performed and the expression of each gene was quantified by counting the total number of reads mapped to its exonic regions. Similarly, the quantity of each spike-in transcript was measured by counting the number of reads mapped to the spike-in reference sequences.
1.2 Data loading
We convert the blocking factor to a factor so that downstream steps do not treat it as an integer.
We rename the rows of our SingleCellExperiment with the symbols, reverting to Ensembl identifiers for missing or duplicate symbols.
library(AnnotationHub)
ens.mm.v97 <- AnnotationHub()[["AH73905"]]
rowData(sce.416b)$ENSEMBL <- rownames(sce.416b)
rowData(sce.416b)$SYMBOL <- mapIds(ens.mm.v97, keys=rownames(sce.416b),
keytype="GENEID", column="SYMBOL")
rowData(sce.416b)$SEQNAME <- mapIds(ens.mm.v97, keys=rownames(sce.416b),
keytype="GENEID", column="SEQNAME")
library(scater)
rownames(sce.416b) <- uniquifyFeatureNames(rowData(sce.416b)$ENSEMBL,
rowData(sce.416b)$SYMBOL)1.3 Quality control
We save an unfiltered copy of the SingleCellExperiment for later use.
Technically, we do not need to use the mitochondrial proportions as we already have the spike-in proportions (which serve a similar purpose) for this dataset. However, it probably doesn’t do any harm to include it anyway.
mito <- which(rowData(sce.416b)$SEQNAME=="MT")
stats <- perCellQCMetrics(sce.416b, subsets=list(Mt=mito))
qc <- quickPerCellQC(stats, percent_subsets=c("subsets_Mt_percent",
"altexps_ERCC_percent"), batch=sce.416b$block)
sce.416b <- sce.416b[,!qc$discard]colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$block <- factor(unfiltered$block)
unfiltered$discard <- qc$discard
gridExtra::grid.arrange(
plotColData(unfiltered, x="block", y="sum",
colour_by="discard") + scale_y_log10() + ggtitle("Total count"),
plotColData(unfiltered, x="block", y="detected",
colour_by="discard") + scale_y_log10() + ggtitle("Detected features"),
plotColData(unfiltered, x="block", y="subsets_Mt_percent",
colour_by="discard") + ggtitle("Mito percent"),
plotColData(unfiltered, x="block", y="altexps_ERCC_percent",
colour_by="discard") + ggtitle("ERCC percent"),
nrow=2,
ncol=2
)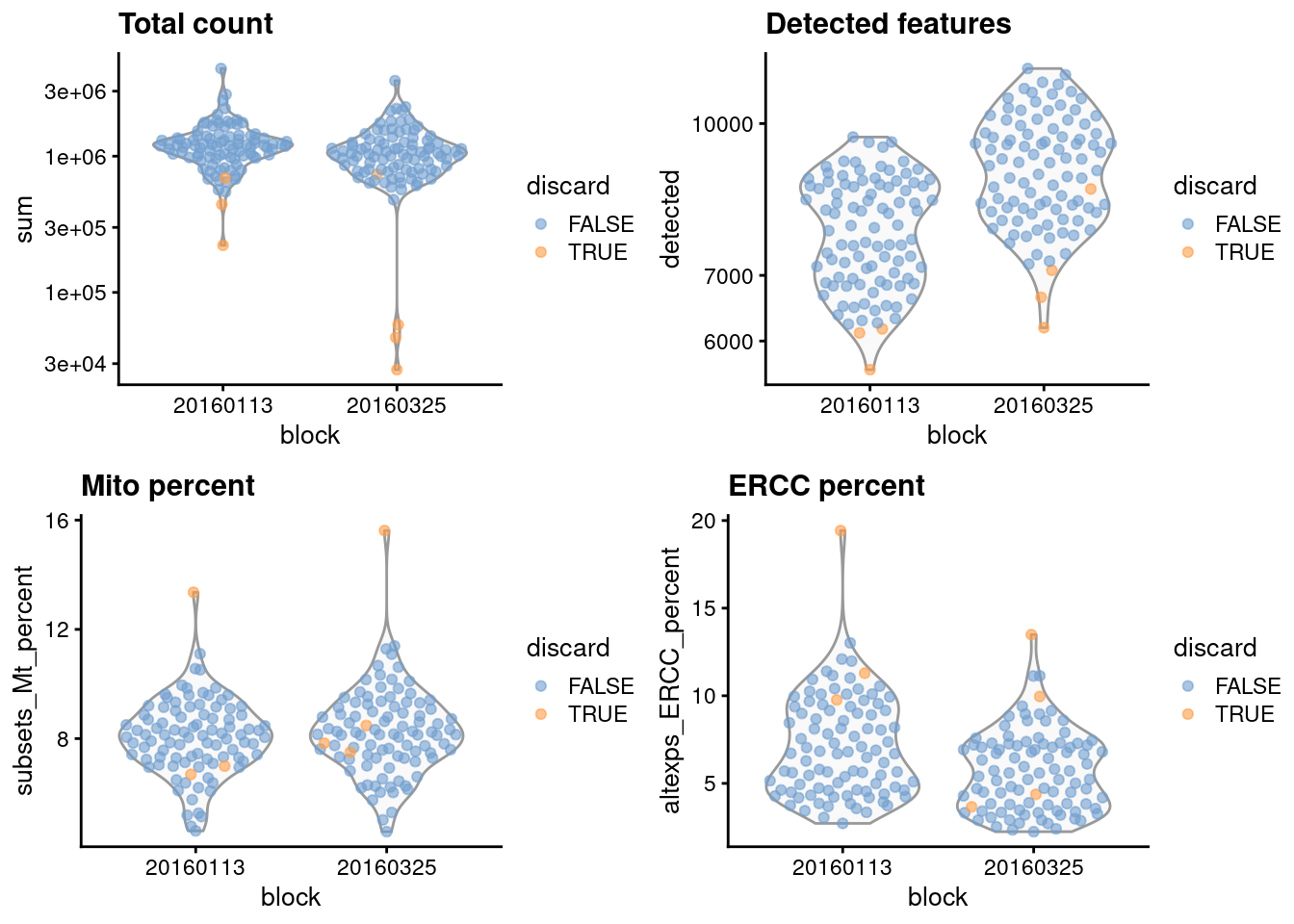
Figure 1.1: Distribution of each QC metric across cells in the 416B dataset, stratified by the plate of origin. Each point represents a cell and is colored according to whether that cell was discarded.
gridExtra::grid.arrange(
plotColData(unfiltered, x="sum", y="subsets_Mt_percent",
colour_by="discard") + scale_x_log10(),
plotColData(unfiltered, x="altexps_ERCC_percent", y="subsets_Mt_percent",
colour_by="discard"),
ncol=2
)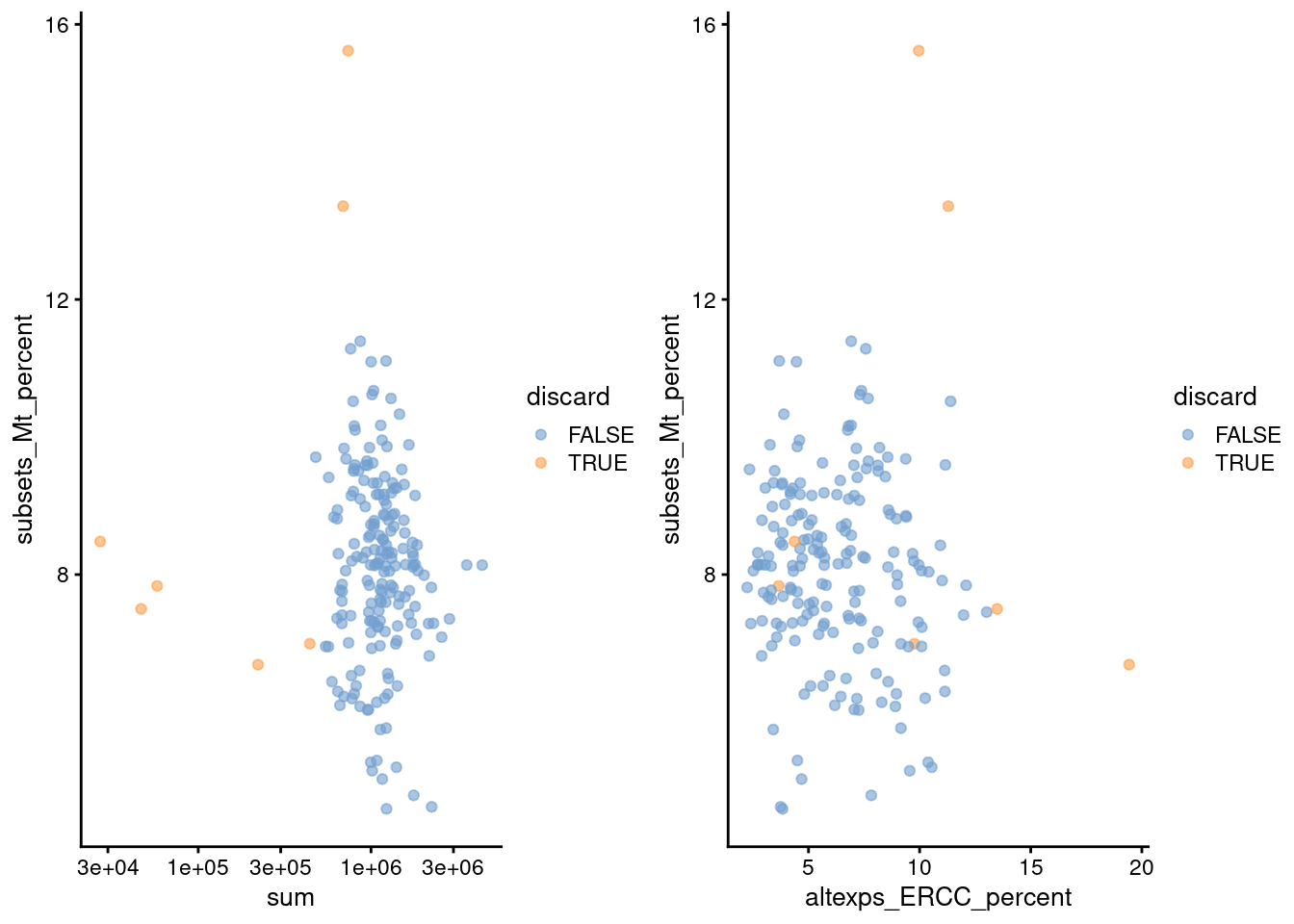
Figure 1.2: Percentage of mitochondrial reads in each cell in the 416B dataset, compared to the total count (left) or the percentage of spike-in reads (right). Each point represents a cell and is colored according to whether that cell was discarded.
We also examine the number of cells removed for each reason.
## low_lib_size low_n_features high_subsets_Mt_percent
## 5 0 2
## high_altexps_ERCC_percent discard
## 2 71.4 Normalization
No pre-clustering is performed here, as the dataset is small and all cells are derived from the same cell line anyway.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.347 0.711 0.921 1.000 1.152 3.604We see that the induced cells have size factors that are systematically shifted from the uninduced cells, consistent with the presence of a composition bias (Figure 1.3).
plot(librarySizeFactors(sce.416b), sizeFactors(sce.416b), pch=16,
xlab="Library size factors", ylab="Deconvolution factors",
col=c("black", "red")[grepl("induced", sce.416b$phenotype)+1],
log="xy")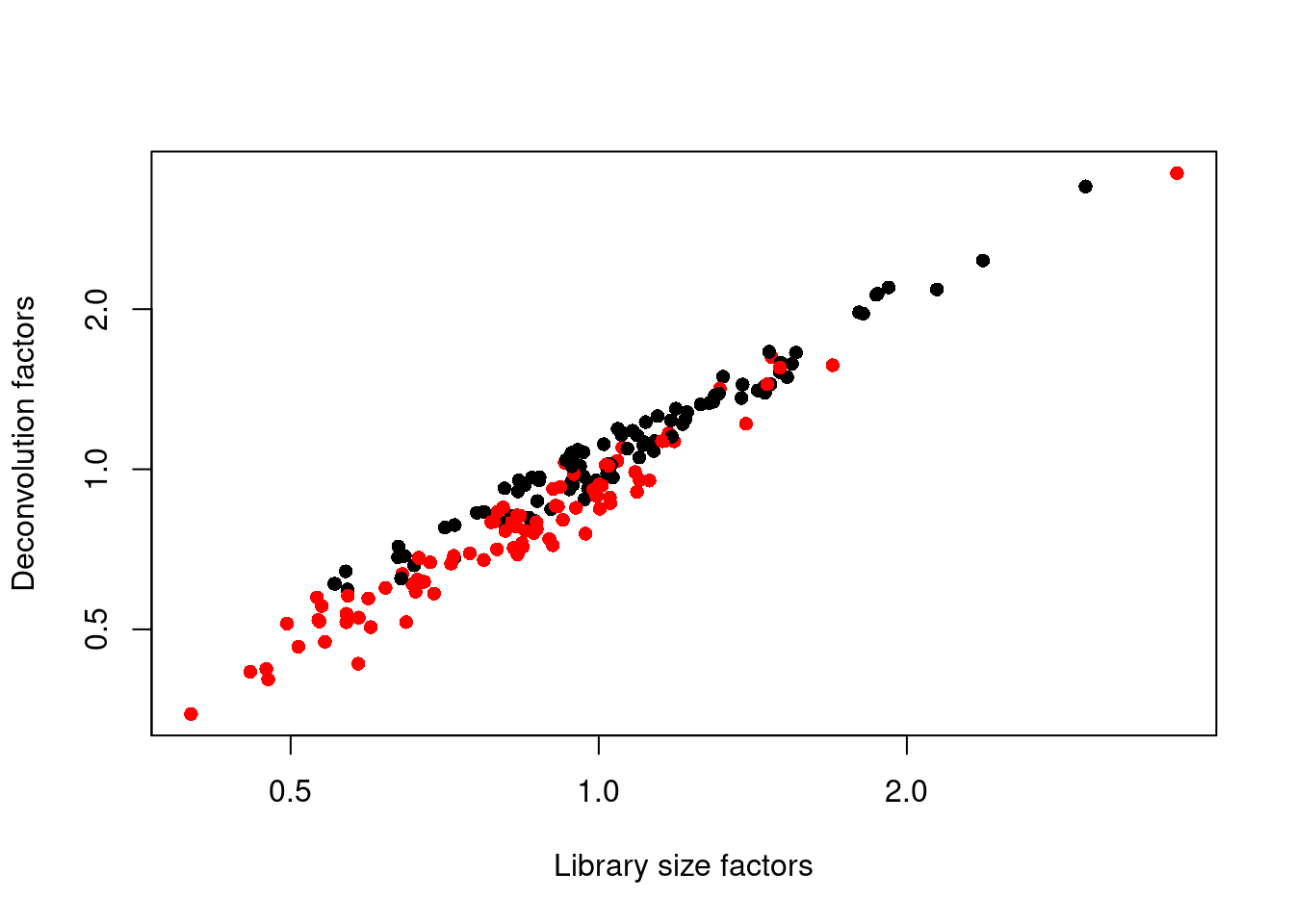
Figure 1.3: Relationship between the library size factors and the deconvolution size factors in the 416B dataset. Each cell is colored according to its oncogene induction status.
1.5 Variance modelling
We block on the plate of origin to minimize plate effects, and then we take the top 10% of genes with the largest biological components.
dec.416b <- modelGeneVarWithSpikes(sce.416b, "ERCC", block=sce.416b$block)
chosen.hvgs <- getTopHVGs(dec.416b, prop=0.1)par(mfrow=c(1,2))
blocked.stats <- dec.416b$per.block
for (i in colnames(blocked.stats)) {
current <- blocked.stats[[i]]
plot(current$mean, current$total, main=i, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(current)
points(curfit$mean, curfit$var, col="red", pch=16)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)
}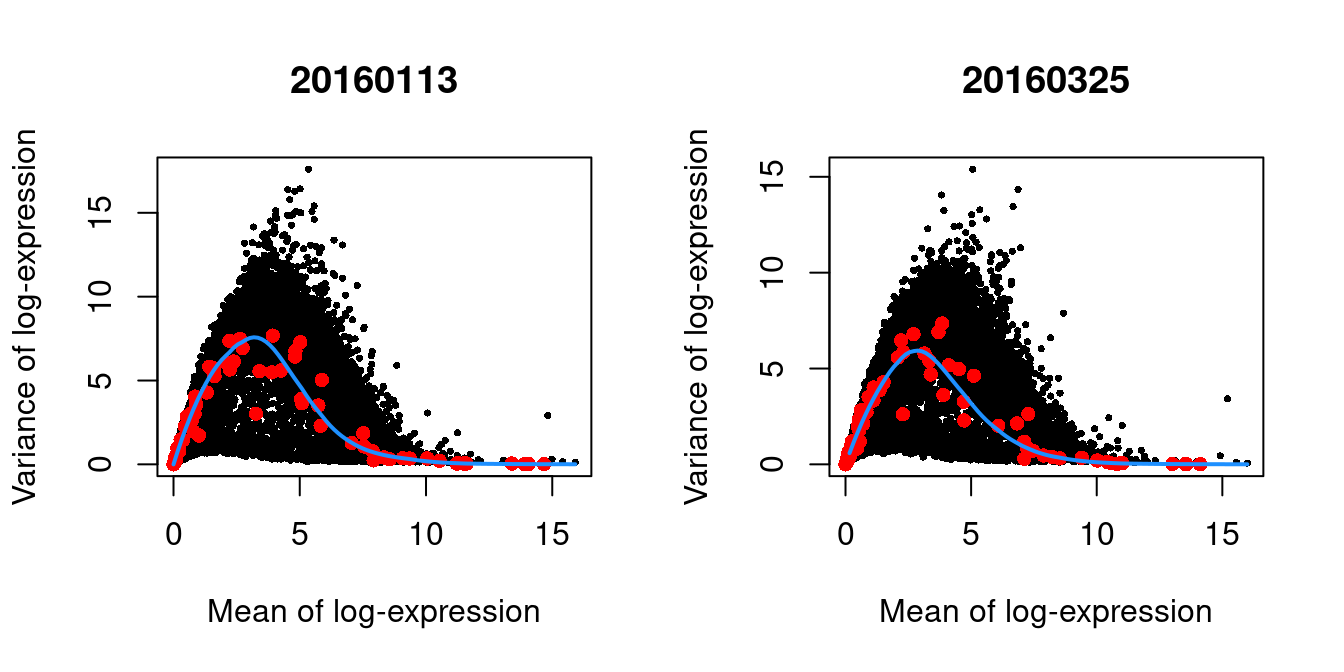
Figure 1.4: Per-gene variance as a function of the mean for the log-expression values in the 416B dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to the spike-in transcripts (red). This was performed separately for each plate.
1.6 Batch correction
The composition of cells is expected to be the same across the two plates,
hence the use of removeBatchEffect() rather than more complex methods.
For larger datasets, consider using regressBatches() from the batchelor package.
1.7 Dimensionality reduction
We do not expect a great deal of heterogeneity in this dataset, so we only request 10 PCs. We use an exact SVD to avoid warnings from irlba about handling small datasets.
1.8 Clustering
my.dist <- dist(reducedDim(sce.416b, "PCA"))
my.tree <- hclust(my.dist, method="ward.D2")
library(dynamicTreeCut)
my.clusters <- unname(cutreeDynamic(my.tree, distM=as.matrix(my.dist),
minClusterSize=10, verbose=0))
colLabels(sce.416b) <- factor(my.clusters)We compare the clusters to the plate of origin. Each cluster is comprised of cells from both batches, indicating that the clustering is not driven by a batch effect.
## Plate
## Cluster 20160113 20160325
## 1 40 38
## 2 37 32
## 3 10 14
## 4 6 8We compare the clusters to the oncogene induction status. We observe differences in in the composition of each cluster, consistent with a biological effect of oncogene induction.
## Oncogene
## Cluster induced CBFB-MYH11 oncogene expression wild type phenotype
## 1 78 0
## 2 0 69
## 3 1 23
## 4 14 0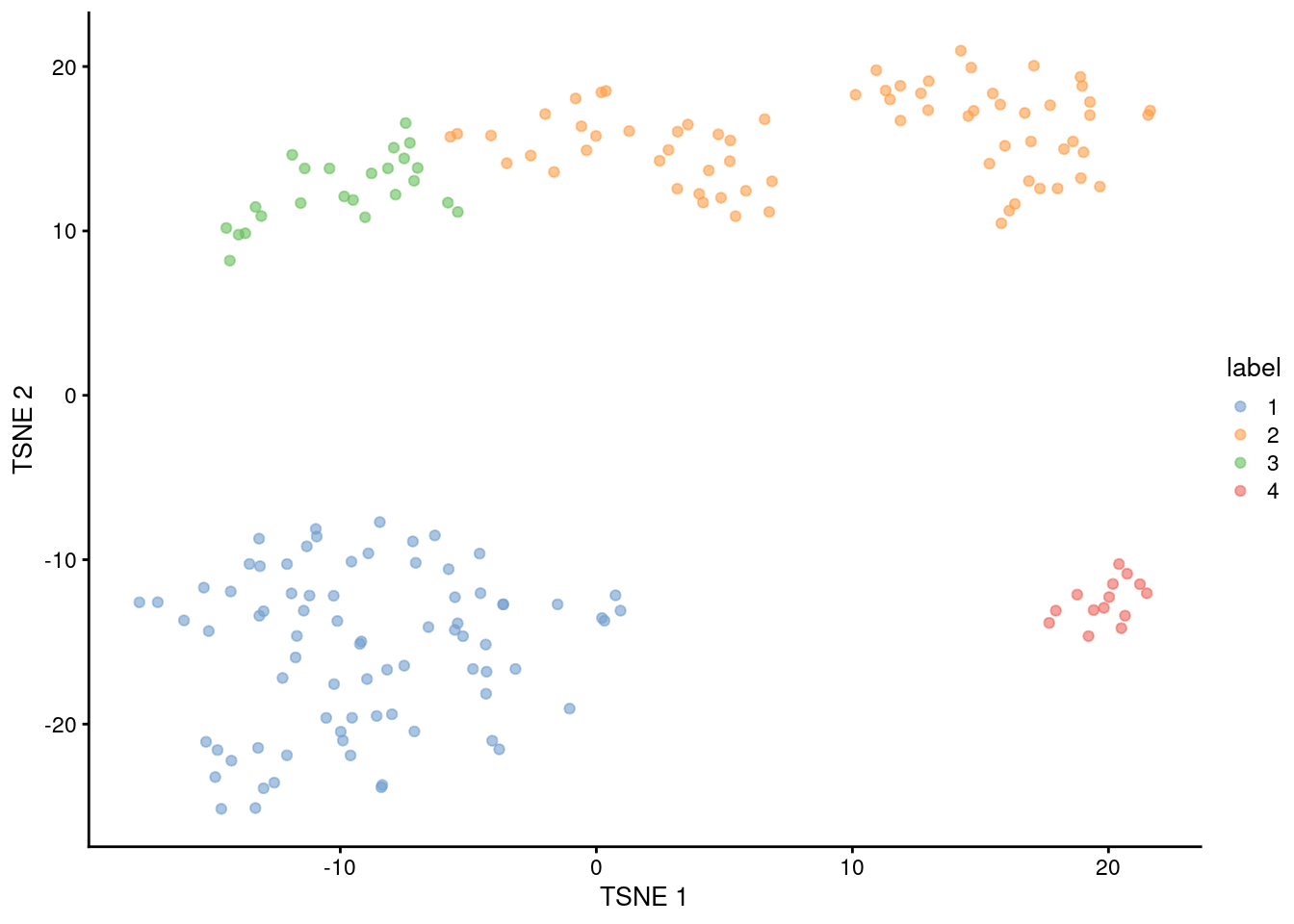
Figure 1.5: Obligatory \(t\)-SNE plot of the 416B dataset, where each point represents a cell and is colored according to the assigned cluster.
Most cells have relatively small positive widths in Figure 1.6, indicating that the separation between clusters is weak. This may be symptomatic of over-clustering where clusters that are clearly defined on oncogene induction status are further split into subsets that are less well separated. Nonetheless, we will proceed with the current clustering scheme as it provides reasonable partitions for further characterization of heterogeneity.
library(cluster)
clust.col <- scater:::.get_palette("tableau10medium") # hidden scater colours
sil <- silhouette(my.clusters, dist = my.dist)
sil.cols <- clust.col[ifelse(sil[,3] > 0, sil[,1], sil[,2])]
sil.cols <- sil.cols[order(-sil[,1], sil[,3])]
plot(sil, main = paste(length(unique(my.clusters)), "clusters"),
border=sil.cols, col=sil.cols, do.col.sort=FALSE)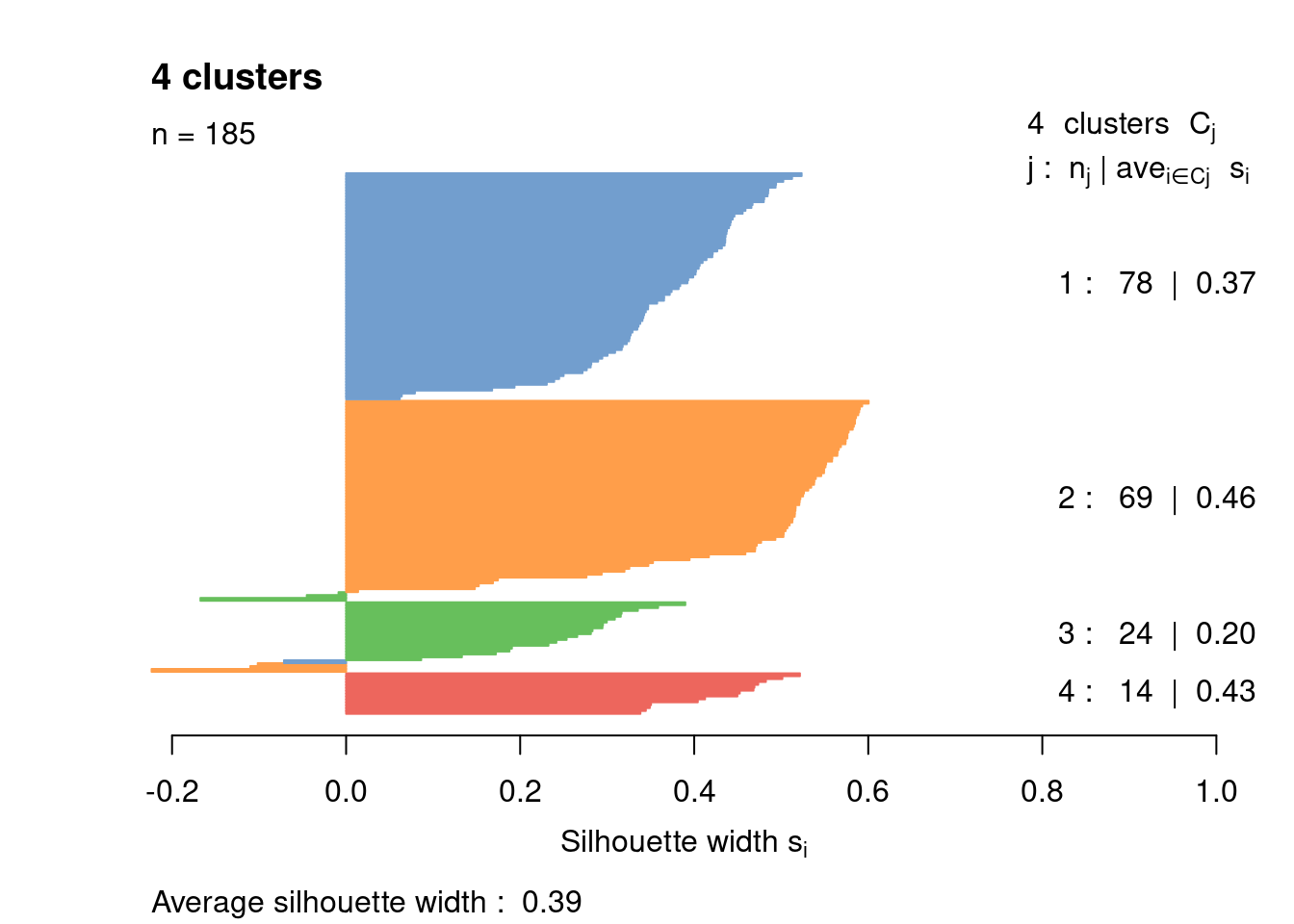
Figure 1.6: Silhouette plot for the hierarchical clustering of the 416B dataset. Each bar represents the silhouette width for a cell and is colored according to the assigned cluster (if positive) or the closest cluster (if negative).
1.9 Interpretation
markers <- findMarkers(sce.416b, my.clusters, block=sce.416b$block)
marker.set <- markers[["1"]]
head(marker.set, 10)## DataFrame with 10 rows and 7 columns
## Top p.value FDR summary.logFC logFC.2 logFC.3
## <integer> <numeric> <numeric> <numeric> <numeric> <numeric>
## Ccna2 1 9.85422e-67 4.59246e-62 -7.13310 -7.13310 -2.20632
## Cdca8 1 1.01449e-41 1.52514e-38 -7.26175 -6.00378 -2.03841
## Pirb 1 4.16555e-33 1.95516e-30 5.87820 5.28149 5.87820
## Cks1b 2 2.98233e-40 3.23229e-37 -6.43381 -6.43381 -4.15385
## Aurkb 2 2.41436e-64 5.62593e-60 -6.94063 -6.94063 -1.65534
## Myh11 2 1.28865e-46 3.75353e-43 4.38182 4.38182 4.29290
## Mcm6 3 1.15877e-28 3.69887e-26 -5.44558 -5.44558 -5.82130
## Cdca3 3 5.02047e-45 1.23144e-41 -6.22179 -6.22179 -2.10502
## Top2a 3 7.25965e-61 1.12776e-56 -7.07811 -7.07811 -2.39123
## Mcm2 4 1.50854e-33 7.98908e-31 -5.54197 -5.54197 -6.09178
## logFC.4
## <numeric>
## Ccna2 -7.3451052
## Cdca8 -7.2617478
## Pirb 0.0352849
## Cks1b -6.4385323
## Aurkb -6.4162126
## Myh11 0.9410499
## Mcm6 -3.5804973
## Cdca3 -7.0539510
## Top2a -6.8297343
## Mcm2 -3.8238103We visualize the expression profiles of the top candidates in Figure 1.7 to verify that the DE signature is robust. Most of the top markers have strong and consistent up- or downregulation in cells of cluster 1 compared to some or all of the other clusters. A cursory examination of the heatmap indicates that cluster 1 contains oncogene-induced cells with strong downregulation of DNA replication and cell cycle genes. This is consistent with the potential induction of senescence as an anti-tumorigenic response (Wajapeyee et al. 2010).
top.markers <- rownames(marker.set)[marker.set$Top <= 10]
plotHeatmap(sce.416b, features=top.markers, order_columns_by="label",
colour_columns_by=c("label", "block", "phenotype"),
center=TRUE, symmetric=TRUE, zlim=c(-5, 5)) 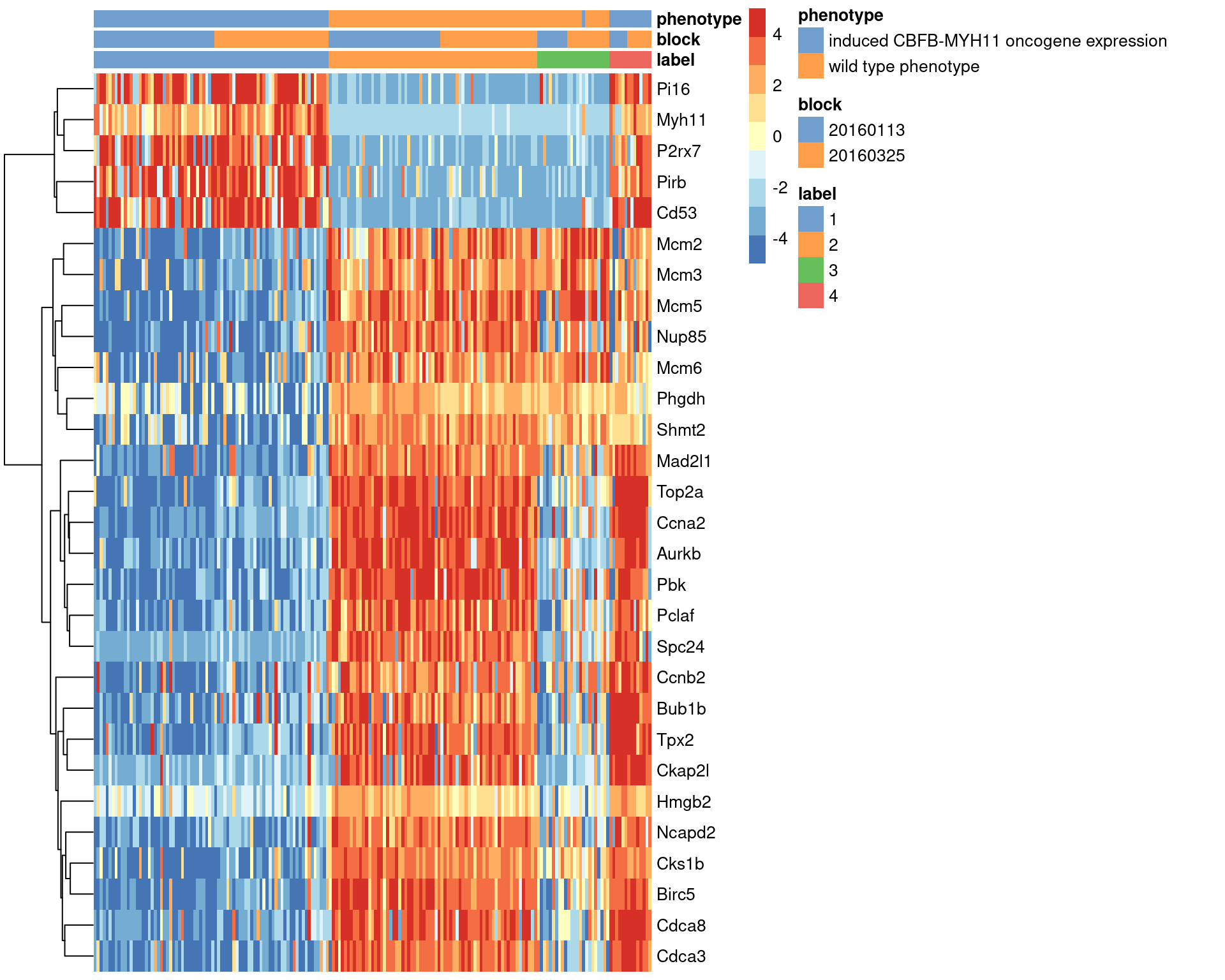
Figure 1.7: Heatmap of the top marker genes for cluster 1 in the 416B dataset, stratified by cluster. The plate of origin and oncogene induction status are also shown for each cell.
Session Info
R version 4.2.1 (2022-06-23)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.5 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.16-bioc/R/lib/libRblas.so
LAPACK: /home/biocbuild/bbs-3.16-bioc/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] cluster_2.1.4 dynamicTreeCut_1.63-1
[3] limma_3.54.0 scran_1.26.0
[5] scater_1.26.0 ggplot2_3.3.6
[7] scuttle_1.8.0 AnnotationHub_3.6.0
[9] BiocFileCache_2.6.0 dbplyr_2.2.1
[11] ensembldb_2.22.0 AnnotationFilter_1.22.0
[13] GenomicFeatures_1.50.0 AnnotationDbi_1.60.0
[15] scRNAseq_2.11.0 SingleCellExperiment_1.20.0
[17] SummarizedExperiment_1.28.0 Biobase_2.58.0
[19] GenomicRanges_1.50.0 GenomeInfoDb_1.34.0
[21] IRanges_2.32.0 S4Vectors_0.36.0
[23] BiocGenerics_0.44.0 MatrixGenerics_1.10.0
[25] matrixStats_0.62.0 BiocStyle_2.26.0
[27] rebook_1.8.0
loaded via a namespace (and not attached):
[1] igraph_1.3.5 lazyeval_0.2.2
[3] BiocParallel_1.32.0 digest_0.6.30
[5] htmltools_0.5.3 viridis_0.6.2
[7] fansi_1.0.3 magrittr_2.0.3
[9] memoise_2.0.1 ScaledMatrix_1.6.0
[11] Biostrings_2.66.0 prettyunits_1.1.1
[13] colorspace_2.0-3 blob_1.2.3
[15] rappdirs_0.3.3 ggrepel_0.9.1
[17] xfun_0.34 dplyr_1.0.10
[19] crayon_1.5.2 RCurl_1.98-1.9
[21] jsonlite_1.8.3 graph_1.76.0
[23] glue_1.6.2 gtable_0.3.1
[25] zlibbioc_1.44.0 XVector_0.38.0
[27] DelayedArray_0.24.0 BiocSingular_1.14.0
[29] scales_1.2.1 pheatmap_1.0.12
[31] edgeR_3.40.0 DBI_1.1.3
[33] Rcpp_1.0.9 viridisLite_0.4.1
[35] xtable_1.8-4 progress_1.2.2
[37] dqrng_0.3.0 bit_4.0.4
[39] rsvd_1.0.5 metapod_1.6.0
[41] httr_1.4.4 RColorBrewer_1.1-3
[43] dir.expiry_1.6.0 ellipsis_0.3.2
[45] pkgconfig_2.0.3 XML_3.99-0.12
[47] farver_2.1.1 CodeDepends_0.6.5
[49] sass_0.4.2 locfit_1.5-9.6
[51] utf8_1.2.2 labeling_0.4.2
[53] tidyselect_1.2.0 rlang_1.0.6
[55] later_1.3.0 munsell_0.5.0
[57] BiocVersion_3.16.0 tools_4.2.1
[59] cachem_1.0.6 cli_3.4.1
[61] generics_0.1.3 RSQLite_2.2.18
[63] ExperimentHub_2.6.0 evaluate_0.17
[65] stringr_1.4.1 fastmap_1.1.0
[67] yaml_2.3.6 knitr_1.40
[69] bit64_4.0.5 purrr_0.3.5
[71] KEGGREST_1.38.0 sparseMatrixStats_1.10.0
[73] mime_0.12 xml2_1.3.3
[75] biomaRt_2.54.0 compiler_4.2.1
[77] beeswarm_0.4.0 filelock_1.0.2
[79] curl_4.3.3 png_0.1-7
[81] interactiveDisplayBase_1.36.0 statmod_1.4.37
[83] tibble_3.1.8 bslib_0.4.0
[85] stringi_1.7.8 highr_0.9
[87] bluster_1.8.0 lattice_0.20-45
[89] ProtGenerics_1.30.0 Matrix_1.5-1
[91] vctrs_0.5.0 pillar_1.8.1
[93] lifecycle_1.0.3 BiocManager_1.30.19
[95] jquerylib_0.1.4 BiocNeighbors_1.16.0
[97] cowplot_1.1.1 bitops_1.0-7
[99] irlba_2.3.5.1 httpuv_1.6.6
[101] rtracklayer_1.58.0 R6_2.5.1
[103] BiocIO_1.8.0 bookdown_0.29
[105] promises_1.2.0.1 gridExtra_2.3
[107] vipor_0.4.5 codetools_0.2-18
[109] assertthat_0.2.1 rjson_0.2.21
[111] withr_2.5.0 GenomicAlignments_1.34.0
[113] Rsamtools_2.14.0 GenomeInfoDbData_1.2.9
[115] parallel_4.2.1 hms_1.1.2
[117] grid_4.2.1 beachmat_2.14.0
[119] rmarkdown_2.17 DelayedMatrixStats_1.20.0
[121] Rtsne_0.16 shiny_1.7.3
[123] ggbeeswarm_0.6.0 restfulr_0.0.15 References
Lun, A. T. L., F. J. Calero-Nieto, L. Haim-Vilmovsky, B. Gottgens, and J. C. Marioni. 2017. “Assessing the reliability of spike-in normalization for analyses of single-cell RNA sequencing data.” Genome Res. 27 (11): 1795–1806.
Picelli, S., O. R. Faridani, A. K. Bjorklund, G. Winberg, S. Sagasser, and R. Sandberg. 2014. “Full-length RNA-seq from single cells using Smart-seq2.” Nat Protoc 9 (1): 171–81.
Wajapeyee, N., S. Z. Wang, R. W. Serra, P. D. Solomon, A. Nagarajan, X. Zhu, and M. R. Green. 2010. “Senescence induction in human fibroblasts and hematopoietic progenitors by leukemogenic fusion proteins.” Blood 115 (24): 5057–60.