# Human pancreas (multiple technologies) {#merged-pancreas}
## Introduction
For a period in 2016, there was a great deal of interest in using scRNA-seq to profile the human pancreas at cellular resolution
[@muraro2016singlecell;@grun2016denovo;@lawlor2017singlecell;@segerstolpe2016singlecell].
As a consequence, we have a surplus of human pancreas datasets generated by different authors with different technologies,
which provides an ideal use case for demonstrating more complex data integration strategies.
This represents a more challenging application than the PBMC dataset in Chapter \@ref(integrating-datasets) as it involves different sequencing protocols and different patients, most likely with differences in cell type composition.
## The good
We start by considering only two datasets from @muraro2016singlecell and @grun2016denovo.
This is a relatively simple scenario involving very similar protocols (CEL-seq and CEL-seq2) and a similar set of authors.
```r
sce.muraro
```
```
## class: SingleCellExperiment
## dim: 16940 2299
## metadata(0):
## assays(2): counts logcounts
## rownames(16940): ENSG00000268895 ENSG00000121410 ... ENSG00000159840
## ENSG00000074755
## rowData names(2): symbol chr
## colnames(2299): D28-1_1 D28-1_2 ... D30-8_93 D30-8_94
## colData names(4): label donor plate sizeFactor
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(1): ERCC
```
We subset both batches to their common universe of genes;
adjust their scaling to equalize sequencing coverage (not really necessary in this case, as the coverage is already similar, but we will do so anyway for consistency);
and select those genes with positive average biological components for further use.
```r
universe <- intersect(rownames(sce.grun), rownames(sce.muraro))
sce.grun2 <- sce.grun[universe,]
dec.grun2 <- dec.grun[universe,]
sce.muraro2 <- sce.muraro[universe,]
dec.muraro2 <- dec.muraro[universe,]
library(batchelor)
normed.pancreas <- multiBatchNorm(sce.grun2, sce.muraro2)
sce.grun2 <- normed.pancreas[[1]]
sce.muraro2 <- normed.pancreas[[2]]
library(scran)
combined.pan <- combineVar(dec.grun2, dec.muraro2)
chosen.genes <- rownames(combined.pan)[combined.pan$bio > 0]
```
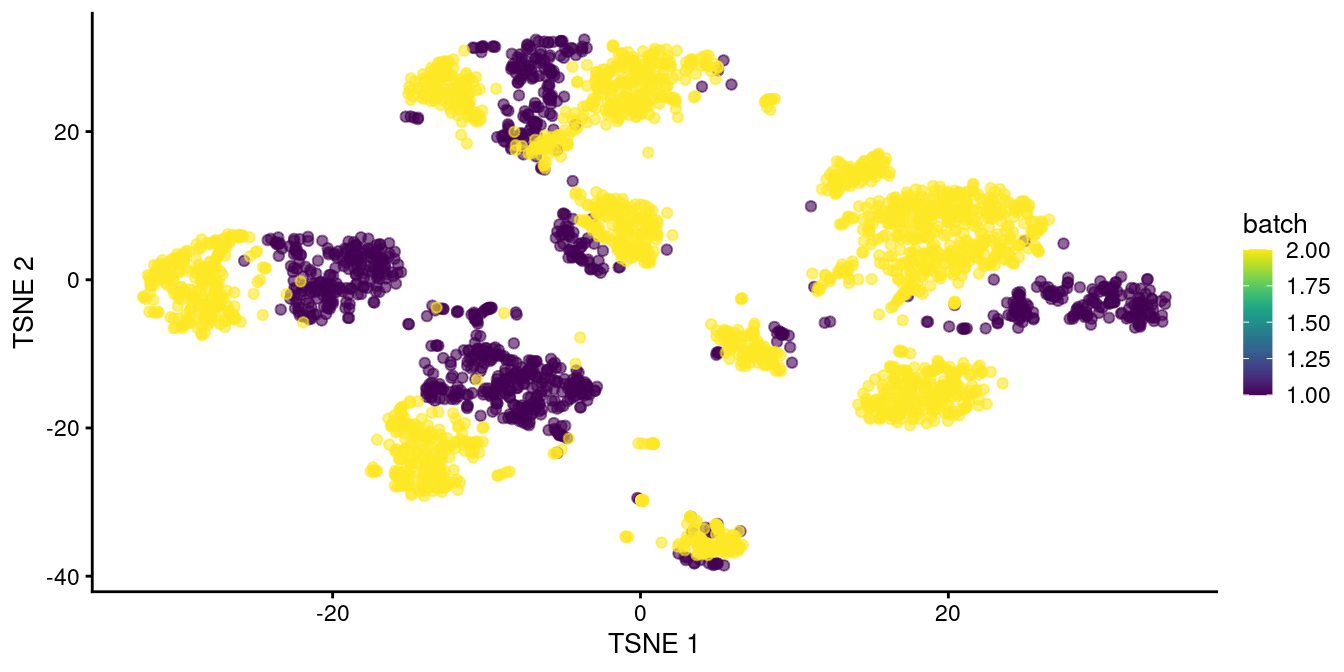
We observe that `rescaleBatches()` is unable to align cells from different batches in Figure \@ref(fig:tsne-pancreas-rescaled).
This is attributable to differences in population composition between batches, with additional complications from non-linearities in the batch effect, e.g., when the magnitude or direction of the batch effect differs between cell types.
```r
library(scater)
rescaled.pancreas <- rescaleBatches(sce.grun2, sce.muraro2)
set.seed(100101)
rescaled.pancreas <- runPCA(rescaled.pancreas, subset_row=chosen.genes,
exprs_values="corrected")
rescaled.pancreas <- runTSNE(rescaled.pancreas, dimred="PCA")
plotTSNE(rescaled.pancreas, colour_by="batch")
```
(\#fig:tsne-pancreas-rescaled)$t$-SNE plot of the two pancreas datasets after correction with `rescaleBatches()`. Each point represents a cell and is colored according to the batch of origin.
Here, we use `fastMNN()` to merge together the two human pancreas datasets described earlier.
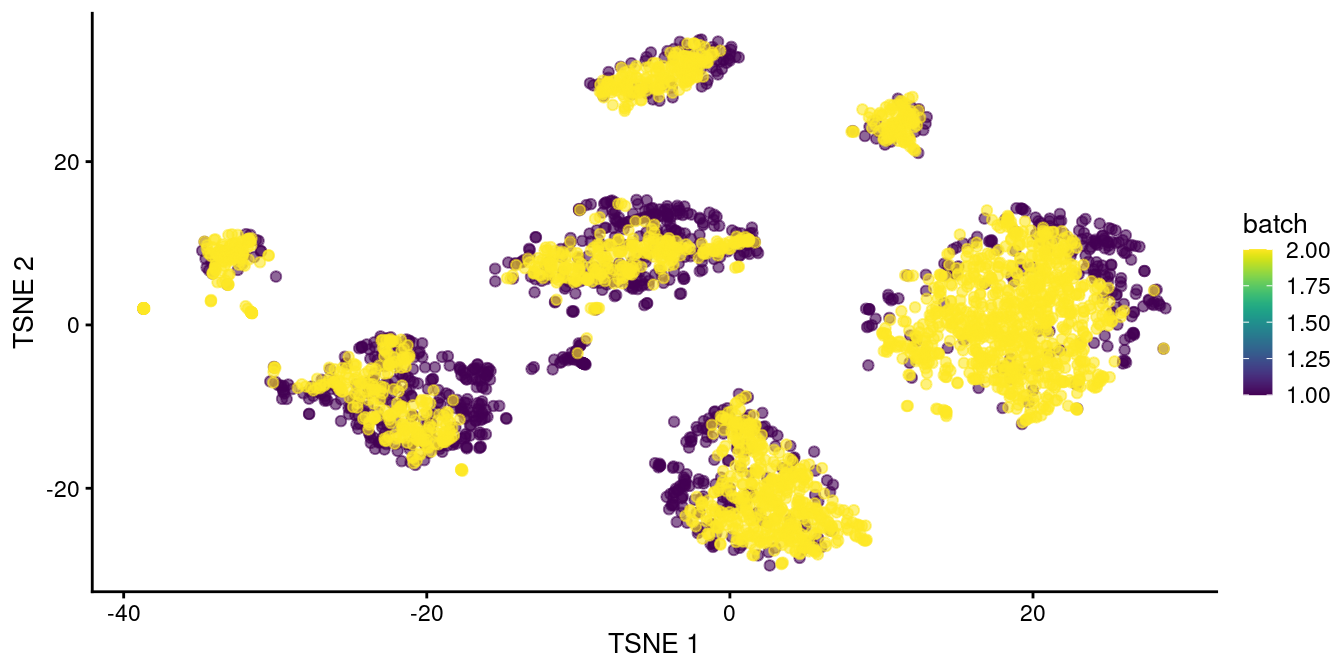
Clustering on the merged datasets yields fewer batch-specific clusters, which is recapitulated as greater intermingling between batches in Figure \@ref(fig:tsne-pancreas-mnn).
This improvement over Figure \@ref(fig:tsne-pancreas-rescaled) represents the ability of `fastMNN()` to adapt to more complex situations involving differences in population composition between batches.
```r
set.seed(1011011)
mnn.pancreas <- fastMNN(sce.grun2, sce.muraro2, subset.row=chosen.genes)
snn.gr <- buildSNNGraph(mnn.pancreas, use.dimred="corrected")
clusters <- igraph::cluster_walktrap(snn.gr)$membership
tab <- table(Cluster=clusters, Batch=mnn.pancreas$batch)
tab
```
```
## Batch
## Cluster 1 2
## 1 241 280
## 2 308 253
## 3 202 839
## 4 36 2
## 5 57 194
## 6 24 108
## 7 109 393
## 8 63 77
## 9 19 117
## 10 0 17
## 11 5 19
```
```r
mnn.pancreas <- runTSNE(mnn.pancreas, dimred="corrected")
plotTSNE(mnn.pancreas, colour_by="batch")
```
(\#fig:tsne-pancreas-mnn)$t$-SNE plot of the two pancreas datasets after correction with `fastMNN()`. Each point represents a cell and is colored according to the batch of origin.
## The bad
Flushed with our previous success, we now attempt to merge the other datasets from @lawlor2017singlecell and @segerstolpe2016singlecell.
This is a more challenging task as it involves different technologies, mixtures of UMI and read count data and a more diverse set of authors (presumably with greater differences in the patient population).
```r
sce.seger
```
```
## class: SingleCellExperiment
## dim: 25454 2090
## metadata(0):
## assays(2): counts logcounts
## rownames(25454): ENSG00000118473 ENSG00000142920 ... ENSG00000278306
## eGFP
## rowData names(2): refseq symbol
## colnames(2090): HP1502401_H13 HP1502401_J14 ... HP1526901T2D_N8
## HP1526901T2D_A8
## colData names(5): CellType Disease Donor Quality sizeFactor
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(1): ERCC
```
We perform the usual routine to obtain re-normalized values and a set of HVGs.
Here, we put all the objects into a list to avoid having to explicitly type their names separately.
```r
all.sce <- list(Grun=sce.grun, Muraro=sce.muraro,
Lawlor=sce.lawlor, Seger=sce.seger)
all.dec <- list(Grun=dec.grun, Muraro=dec.muraro,
Lawlor=dec.lawlor, Seger=dec.seger)
universe <- Reduce(intersect, lapply(all.sce, rownames))
all.sce <- lapply(all.sce, "[", i=universe,)
all.dec <- lapply(all.dec, "[", i=universe,)
normed.pancreas <- do.call(multiBatchNorm, all.sce)
combined.pan <- do.call(combineVar, all.dec)
chosen.genes <- rownames(combined.pan)[combined.pan$bio > 0]
```
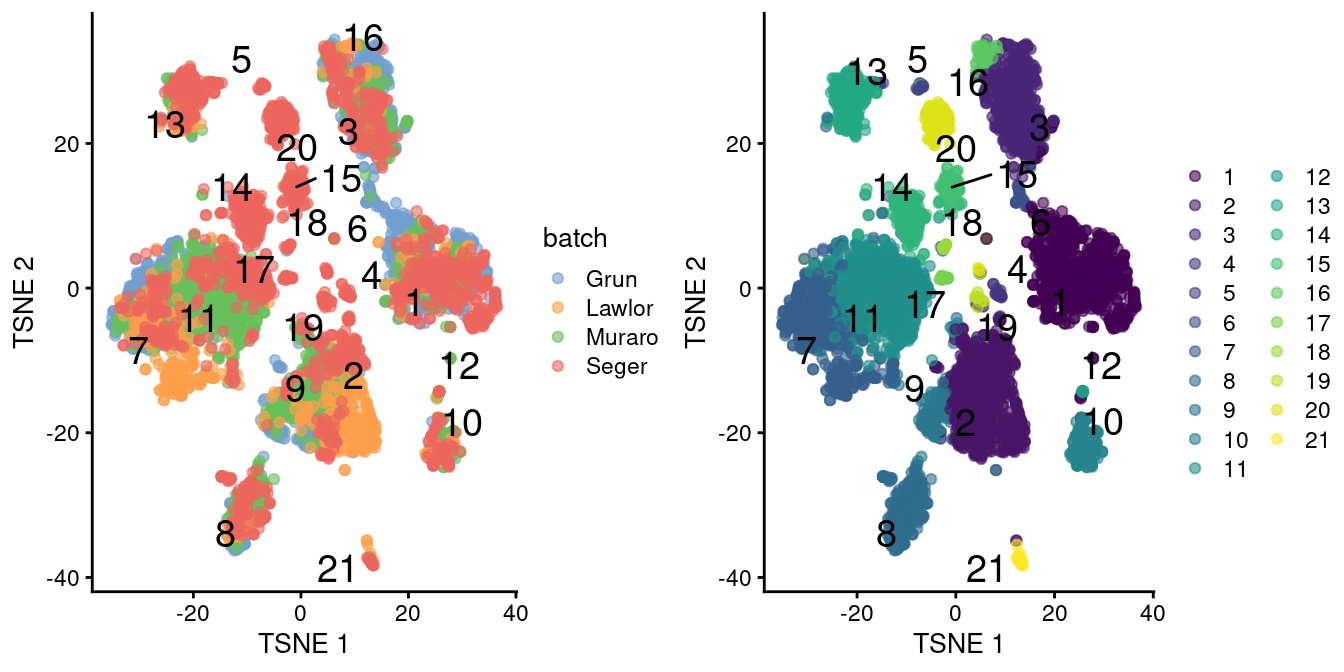
We observe that the merge is generally successful, with many clusters containing contributions from each batch (Figure \@ref(fig:tsne-pancreas-mnn-many)).
There are few clusters that are specific to the Segerstolpe dataset, and if we were naive, we might consider them to represent interesting subpopulations that are not present in the other datasets.
```r
set.seed(1011110)
mnn.pancreas <- fastMNN(normed.pancreas)
# Bumping up 'k' to get broader clusters for this demonstration.
snn.gr <- buildSNNGraph(mnn.pancreas, use.dimred="corrected", k=20)
clusters <- igraph::cluster_walktrap(snn.gr)$membership
clusters <- factor(clusters)
tab <- table(Cluster=clusters, Batch=mnn.pancreas$batch)
tab
```
```
## Batch
## Cluster Grun Lawlor Muraro Seger
## 1 309 28 259 386
## 2 108 244 386 186
## 3 223 17 250 149
## 4 0 0 0 42
## 5 0 0 0 41
## 6 34 0 1 0
## 7 129 216 176 118
## 8 57 17 196 109
## 9 63 9 77 11
## 10 24 18 107 55
## 11 72 21 661 196
## 12 0 1 16 4
## 13 19 18 118 156
## 14 0 0 1 206
## 15 0 0 0 113
## 16 20 5 27 36
## 17 0 0 0 26
## 18 1 2 5 11
## 19 0 0 0 42
## 20 0 0 0 186
## 21 5 8 19 17
```
```r
mnn.pancreas <- runTSNE(mnn.pancreas, dimred="corrected")
gridExtra::grid.arrange(
plotTSNE(mnn.pancreas, colour_by="batch", text_by=I(clusters)),
plotTSNE(mnn.pancreas, colour_by=I(clusters), text_by=I(clusters)),
ncol=2
)
```
(\#fig:tsne-pancreas-mnn-many)$t$-SNE plots of the four pancreas datasets after correction with `fastMNN()`. Each point represents a cell and is colored according to the batch of origin (left) or the assigned cluster (right). The cluster label is shown at the median location across all cells in the cluster.
Fortunately, we are battle-hardened and cynical, so we are sure to check for other sources of variation.
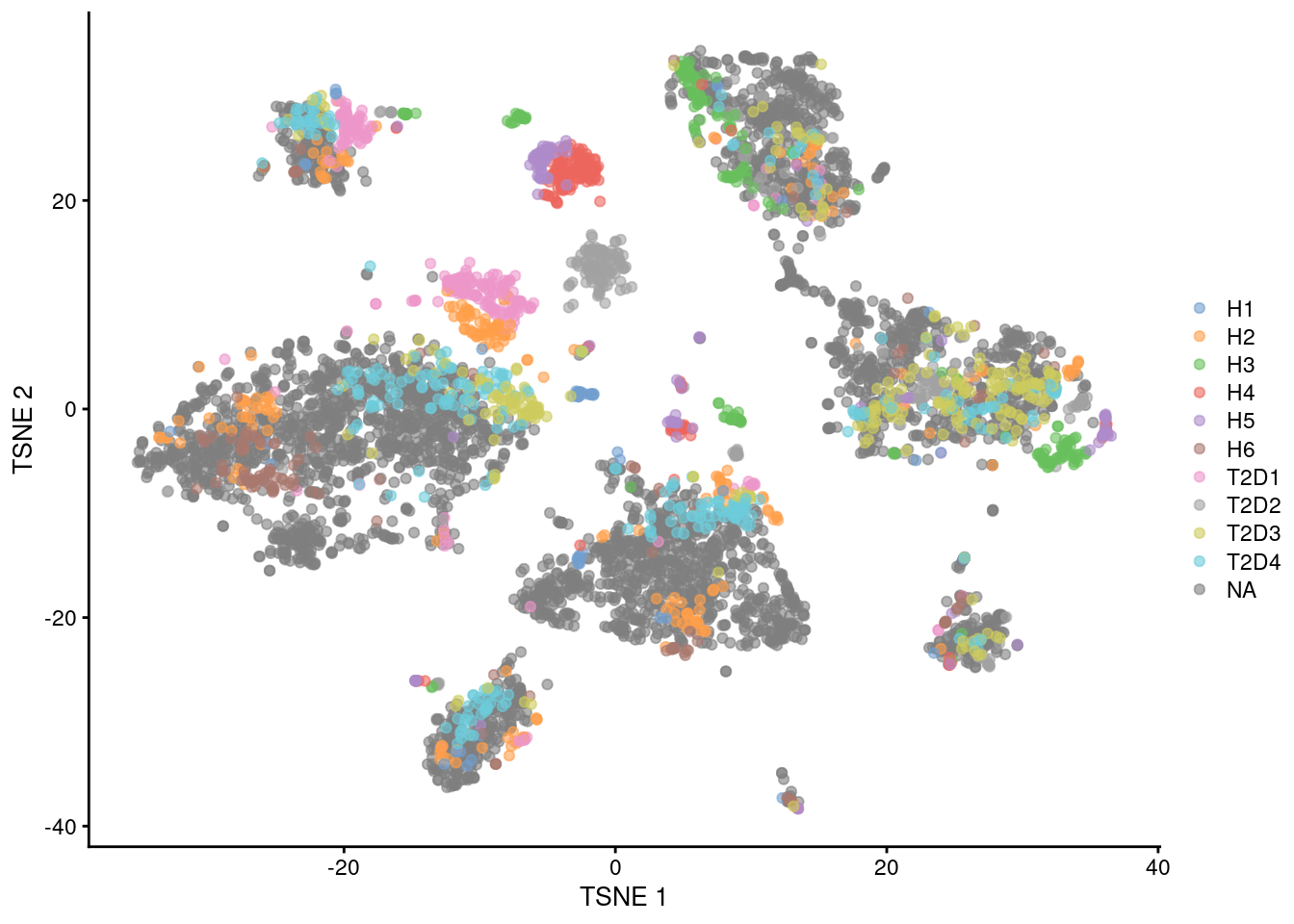
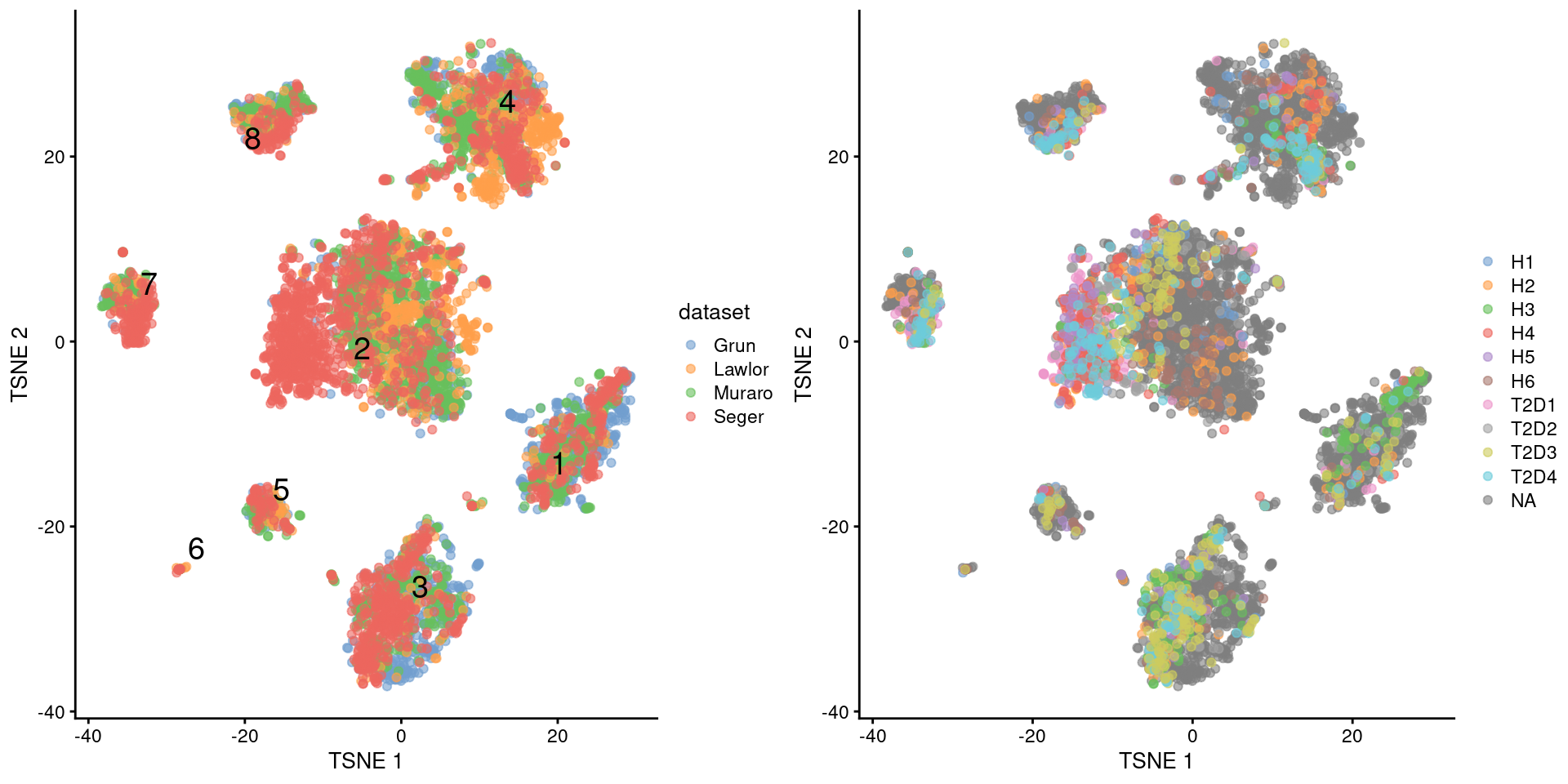
The most obvious candidate is the donor of origin for each cell (Figure \@ref(fig:tsne-pancreas-mnn-donor)), which correlates strongly to these Segerstolpe-only clusters.
This is not surprising given the large differences between humans in the wild, but donor-level variation is not interesting for the purposes of cell type characterization.
(That said, preservation of the within-dataset donor effects is the technically correct course of action here, as a batch correction method should try to avoid removing heterogeneity within each of its defined batches.)
```r
donors <- c(
normed.pancreas$Grun$donor,
normed.pancreas$Muraro$donor,
normed.pancreas$Lawlor$`islet unos id`,
normed.pancreas$Seger$Donor
)
seger.donors <- donors
seger.donors[mnn.pancreas$batch!="Seger"] <- NA
plotTSNE(mnn.pancreas, colour_by=I(seger.donors))
```
(\#fig:tsne-pancreas-mnn-donor)$t$-SNE plots of the four pancreas datasets after correction with `fastMNN()`. Each point represents a cell and is colored according to the donor of origin for the Segerstolpe dataset.
## The ugly
Given these results, the most prudent course of action is to remove the donor effects within each dataset in addition to the batch effects across datasets.
This involves a bit more work to properly specify the two levels of unwanted heterogeneity.
To make our job a bit easier, we use the `noCorrect()` utility to combine all batches into a single `SingleCellExperiment` object.
```r
combined <- noCorrect(normed.pancreas)
assayNames(combined) <- "logcounts"
combined$donor <- donors
```
We then call `fastMNN()` on the combined object with our chosen HVGs, using the `batch=` argument to specify which cells belong to which donors.
This will progressively merge cells from each donor in each batch until all cells are mapped onto a common coordinate space.
For some extra sophistication, we also set the `weights=` argument to ensure that each batch contributes equally to the PCA, regardless of the number of donors present in that batch; see `?multiBatchPCA` for more details.
```r
donors.per.batch <- split(combined$donor, combined$batch)
donors.per.batch <- lapply(donors.per.batch, unique)
donors.per.batch
```
```
## $Grun
## [1] "D2" "D3" "D7" "D10" "D17"
##
## $Lawlor
## [1] "ACIW009" "ACJV399" "ACCG268" "ACCR015A" "ACEK420A" "ACEL337" "ACHY057"
## [8] "ACIB065"
##
## $Muraro
## [1] "D28" "D29" "D31" "D30"
##
## $Seger
## [1] "H2" "T2D1" "H1" "T2D2" "H3" "H4" "H5" "H6" "T2D3" "T2D4"
```
```r
set.seed(1010100)
multiout <- fastMNN(combined, batch=combined$donor,
subset.row=chosen.genes, weights=donors.per.batch)
# Renaming metadata fields for easier communication later.
multiout$dataset <- combined$batch
multiout$donor <- multiout$batch
multiout$batch <- NULL
```
With this approach, we see that the Segerstolpe-only clusters have disappeared (Figure \@ref(fig:tsne-pancreas-mnn-donor-all)).
Visually, there also seems to be much greater mixing between cells from different Segerstolpe donors.
This suggests that we have removed most of the donor effect, which simplifies the interpretation of our clusters.
```r
library(scater)
g <- buildSNNGraph(multiout, use.dimred=1, k=50)
clusters <- igraph::cluster_walktrap(g)$membership
tab <- table(clusters, multiout$dataset)
tab
```
```
##
## clusters Grun Lawlor Muraro Seger
## 1 254 20 275 185
## 2 202 241 844 877
## 3 330 29 280 391
## 4 171 253 461 280
## 5 24 17 106 55
## 6 5 8 19 17
## 7 19 19 118 174
## 8 59 17 196 111
```
```r
multiout <- runTSNE(multiout, dimred="corrected")
gridExtra::grid.arrange(
plotTSNE(multiout, colour_by="dataset", text_by=I(clusters)),
plotTSNE(multiout, colour_by=I(seger.donors)),
ncol=2
)
```
(\#fig:tsne-pancreas-mnn-donor-all)$t$-SNE plots of the four pancreas datasets after donor-level correction with `fastMNN()`. Each point represents a cell and is colored according to the batch of origin (left) or the donor of origin for the Segerstolpe-derived cells (right). The cluster label is shown at the median location across all cells in the cluster.
Our clusters compare well to the published annotations, indicating that we did not inadvertently discard important factors of variation during correction.
(Though in this case, the cell types are so well defined, it would be quite a feat to fail to separate them!)
```r
proposed <- c(rep(NA, ncol(sce.grun)),
sce.muraro$label,
sce.lawlor$`cell type`,
sce.seger$CellType)
proposed <- tolower(proposed)
proposed[proposed=="gamma/pp"] <- "gamma"
proposed[proposed=="pp"] <- "gamma"
proposed[proposed=="duct"] <- "ductal"
proposed[proposed=="psc"] <- "stellate"
table(proposed, clusters)
```
```
## clusters
## proposed 1 2 3 4 5 6 7 8
## acinar 419 1 4 0 0 1 0 0
## alpha 1 1865 6 10 0 1 2 2
## beta 3 3 5 920 2 0 7 0
## co-expression 0 8 0 30 0 0 0 1
## delta 0 1 2 3 0 1 0 309
## ductal 5 1 624 4 5 0 1 0
## endothelial 0 0 0 0 1 33 0 0
## epsilon 0 1 0 0 0 0 7 0
## gamma 2 0 0 0 0 0 280 0
## mesenchymal 0 0 1 0 79 0 0 0
## mhc class ii 0 0 4 0 0 0 0 0
## nana 2 13 8 1 0 1 0 1
## none/other 0 2 4 1 0 4 1 0
## stellate 0 0 1 0 70 1 0 0
## unclassified 0 0 0 0 2 0 0 0
## unclassified endocrine 0 3 0 2 0 0 0 1
## unclear 0 0 4 0 0 0 0 0
```
## Session Info {-}