# Paul mouse HSC (MARS-seq)
## Introduction
This performs an analysis of the mouse haematopoietic stem cell (HSC) dataset generated with MARS-seq [@paul2015transcriptional].
Cells were extracted from multiple mice under different experimental conditions (i.e., sorting protocols) and libraries were prepared using a series of 384-well plates.
## Data loading
```r
library(scRNAseq)
sce.paul <- PaulHSCData(ensembl=TRUE)
```
```r
library(AnnotationHub)
ens.mm.v97 <- AnnotationHub()[["AH73905"]]
anno <- select(ens.mm.v97, keys=rownames(sce.paul),
keytype="GENEID", columns=c("SYMBOL", "SEQNAME"))
rowData(sce.paul) <- anno[match(rownames(sce.paul), anno$GENEID),]
```
After loading and annotation, we inspect the resulting `SingleCellExperiment` object:
```r
sce.paul
```
```
## class: SingleCellExperiment
## dim: 17483 10368
## metadata(0):
## assays(1): counts
## rownames(17483): ENSMUSG00000007777 ENSMUSG00000107002 ...
## ENSMUSG00000039068 ENSMUSG00000064363
## rowData names(3): GENEID SYMBOL SEQNAME
## colnames(10368): W29953 W29954 ... W76335 W76336
## colData names(13): Well_ID Seq_batch_ID ... CD34_measurement
## FcgR3_measurement
## reducedDimNames(0):
## mainExpName: NULL
## altExpNames(0):
```
## Quality control
```r
unfiltered <- sce.paul
```
For some reason, only one mitochondrial transcripts are available, so we will perform quality control using only the library size and number of detected features.
Ideally, we would simply block on the plate of origin to account for differences in processing, but unfortunately, it seems that many plates have a large proportion (if not outright majority) of cells with poor values for both metrics.
We identify such plates based on the presence of very low outlier thresholds, for some arbitrary definition of "low"; we then redefine thresholds using information from the other (presumably high-quality) plates.
```r
library(scater)
stats <- perCellQCMetrics(sce.paul)
qc <- quickPerCellQC(stats, batch=sce.paul$Plate_ID)
# Detecting batches with unusually low threshold values.
lib.thresholds <- attr(qc$low_lib_size, "thresholds")["lower",]
nfeat.thresholds <- attr(qc$low_n_features, "thresholds")["lower",]
ignore <- union(names(lib.thresholds)[lib.thresholds < 100],
names(nfeat.thresholds)[nfeat.thresholds < 100])
# Repeating the QC using only the "high-quality" batches.
qc2 <- quickPerCellQC(stats, batch=sce.paul$Plate_ID,
subset=!sce.paul$Plate_ID %in% ignore)
sce.paul <- sce.paul[,!qc2$discard]
```
We examine the number of cells discarded for each reason.
```r
colSums(as.matrix(qc2))
```
```
## low_lib_size low_n_features discard
## 1695 1781 1783
```
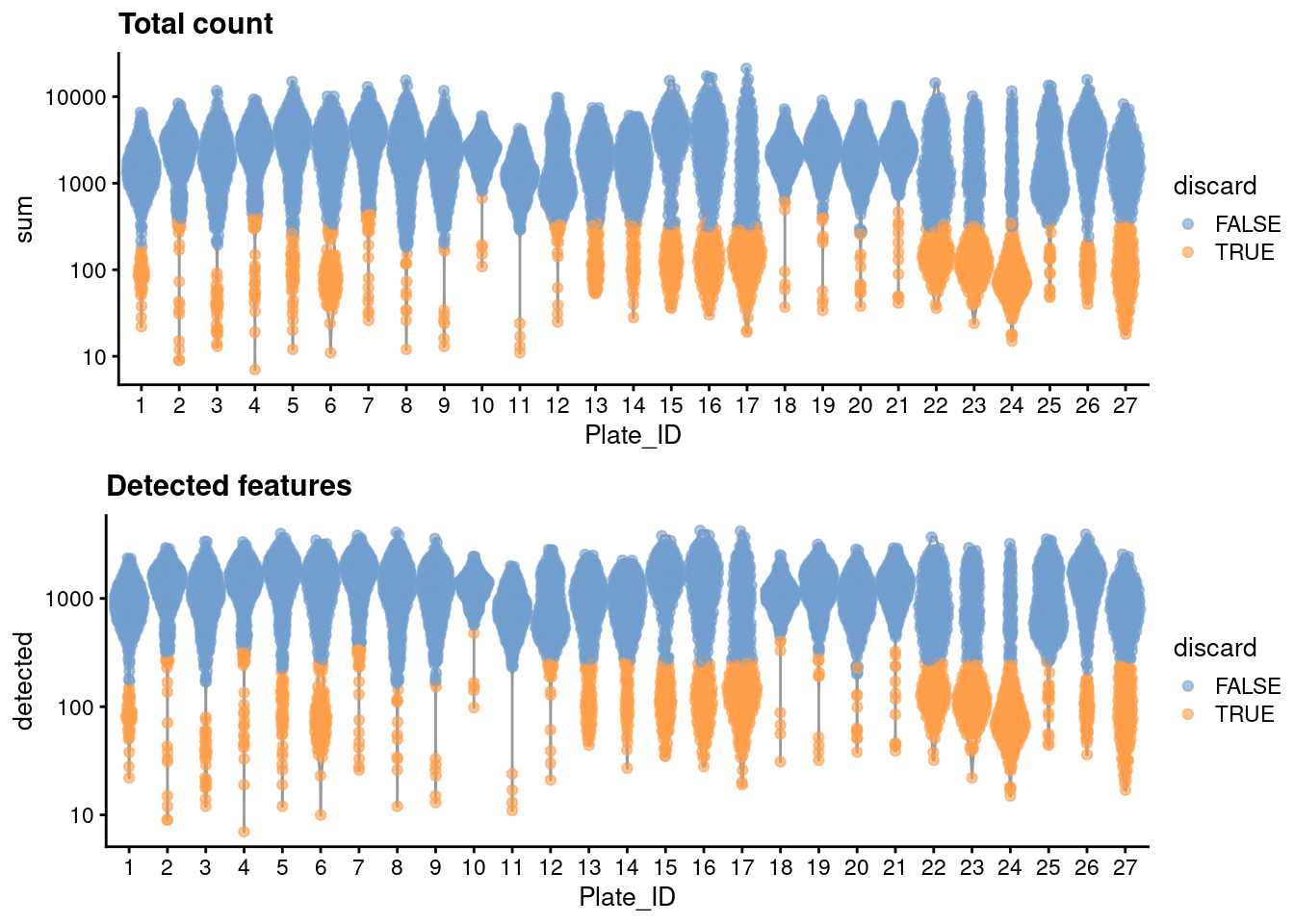
We create some diagnostic plots for each metric (Figure \@ref(fig:unref-paul-qc-dist)).
```r
colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$discard <- qc2$discard
unfiltered$Plate_ID <- factor(unfiltered$Plate_ID)
gridExtra::grid.arrange(
plotColData(unfiltered, y="sum", x="Plate_ID", colour_by="discard") +
scale_y_log10() + ggtitle("Total count"),
plotColData(unfiltered, y="detected", x="Plate_ID", colour_by="discard") +
scale_y_log10() + ggtitle("Detected features"),
ncol=1
)
```
(\#fig:unref-paul-qc-dist)Distribution of each QC metric across cells in the Paul HSC dataset. Each point represents a cell and is colored according to whether that cell was discarded.
## Normalization
```r
library(scran)
set.seed(101000110)
clusters <- quickCluster(sce.paul)
sce.paul <- computeSumFactors(sce.paul, clusters=clusters)
sce.paul <- logNormCounts(sce.paul)
```
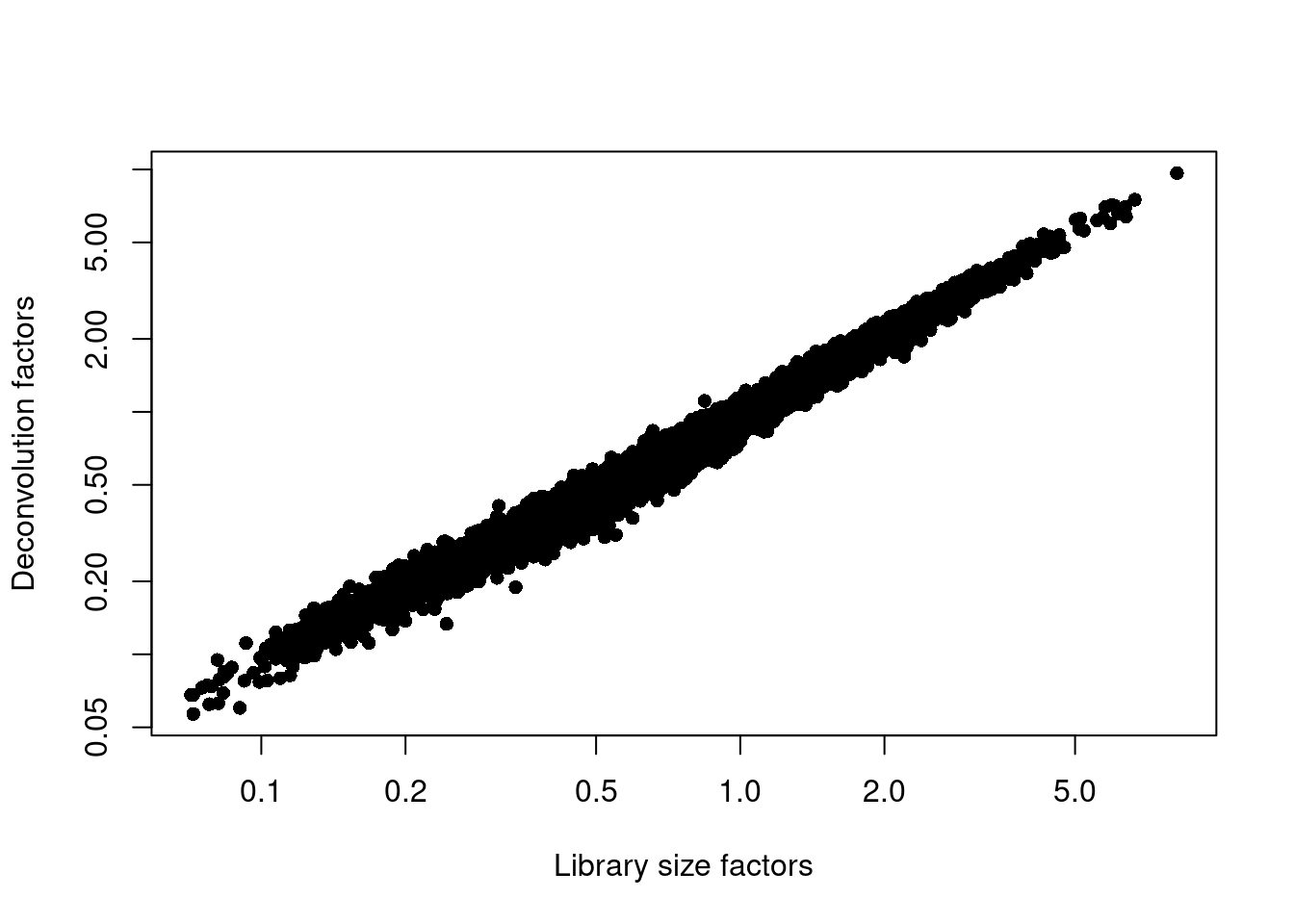
We examine some key metrics for the distribution of size factors, and compare it to the library sizes as a sanity check (Figure \@ref(fig:unref-paul-norm)).
```r
summary(sizeFactors(sce.paul))
```
```
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.057 0.422 0.775 1.000 1.335 9.654
```
```r
plot(librarySizeFactors(sce.paul), sizeFactors(sce.paul), pch=16,
xlab="Library size factors", ylab="Deconvolution factors", log="xy")
```
(\#fig:unref-paul-norm)Relationship between the library size factors and the deconvolution size factors in the Paul HSC dataset.
## Variance modelling
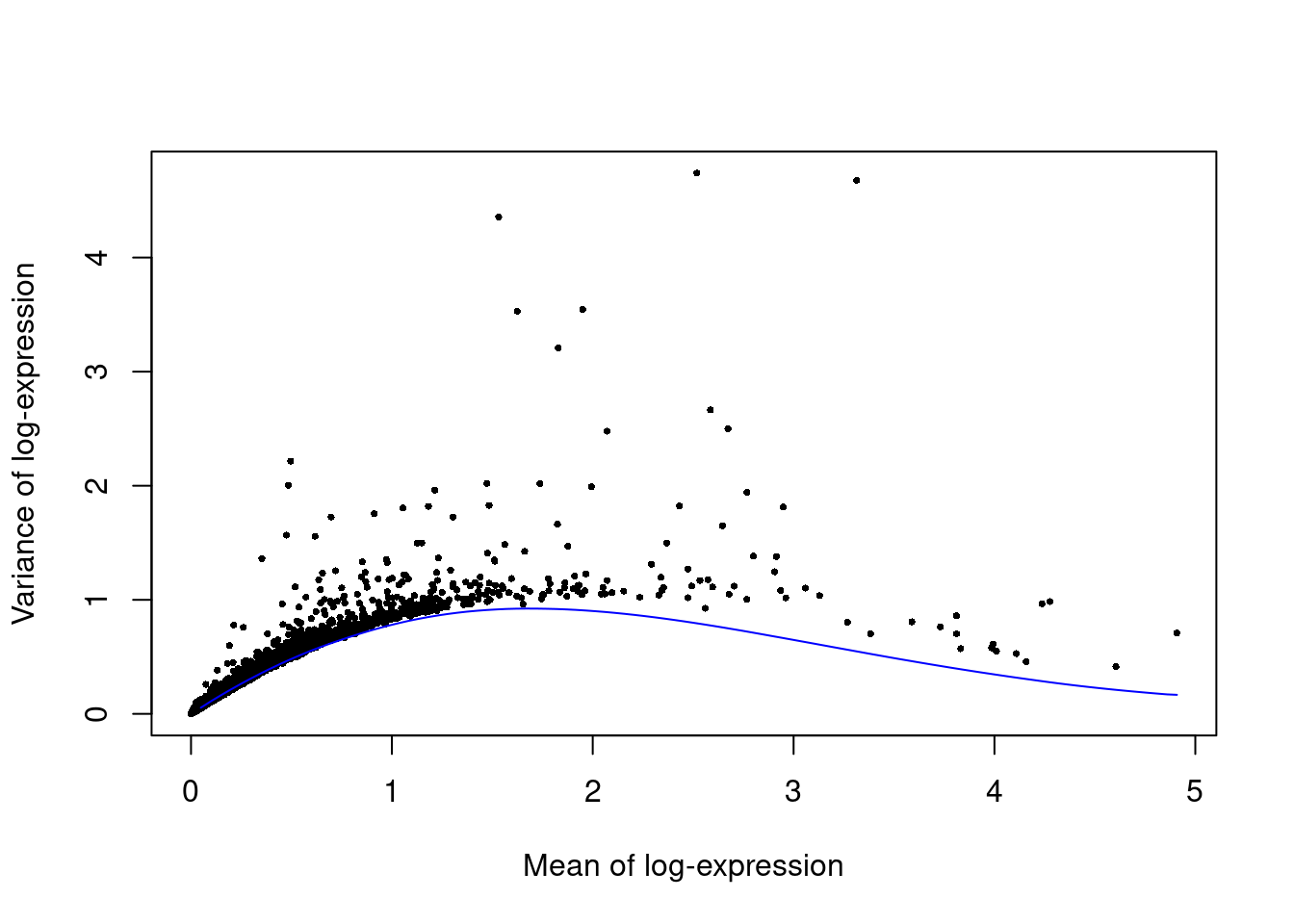
We fit a mean-variance trend to the endogenous genes to detect highly variable genes.
Unfortunately, the plates are confounded with an experimental treatment (`Batch_desc`) so we cannot block on the plate of origin.
```r
set.seed(00010101)
dec.paul <- modelGeneVarByPoisson(sce.paul)
top.paul <- getTopHVGs(dec.paul, prop=0.1)
```
```r
plot(dec.paul$mean, dec.paul$total, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curve(metadata(dec.paul)$trend(x), col="blue", add=TRUE)
```
(\#fig:unref-paul-var)Per-gene variance as a function of the mean for the log-expression values in the Paul HSC dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to simulated Poisson noise.
## Dimensionality reduction
```r
set.seed(101010011)
sce.paul <- denoisePCA(sce.paul, technical=dec.paul, subset.row=top.paul)
sce.paul <- runTSNE(sce.paul, dimred="PCA")
```
We check that the number of retained PCs is sensible.
```r
ncol(reducedDim(sce.paul, "PCA"))
```
```
## [1] 13
```
## Clustering
```r
snn.gr <- buildSNNGraph(sce.paul, use.dimred="PCA", type="jaccard")
colLabels(sce.paul) <- factor(igraph::cluster_louvain(snn.gr)$membership)
```
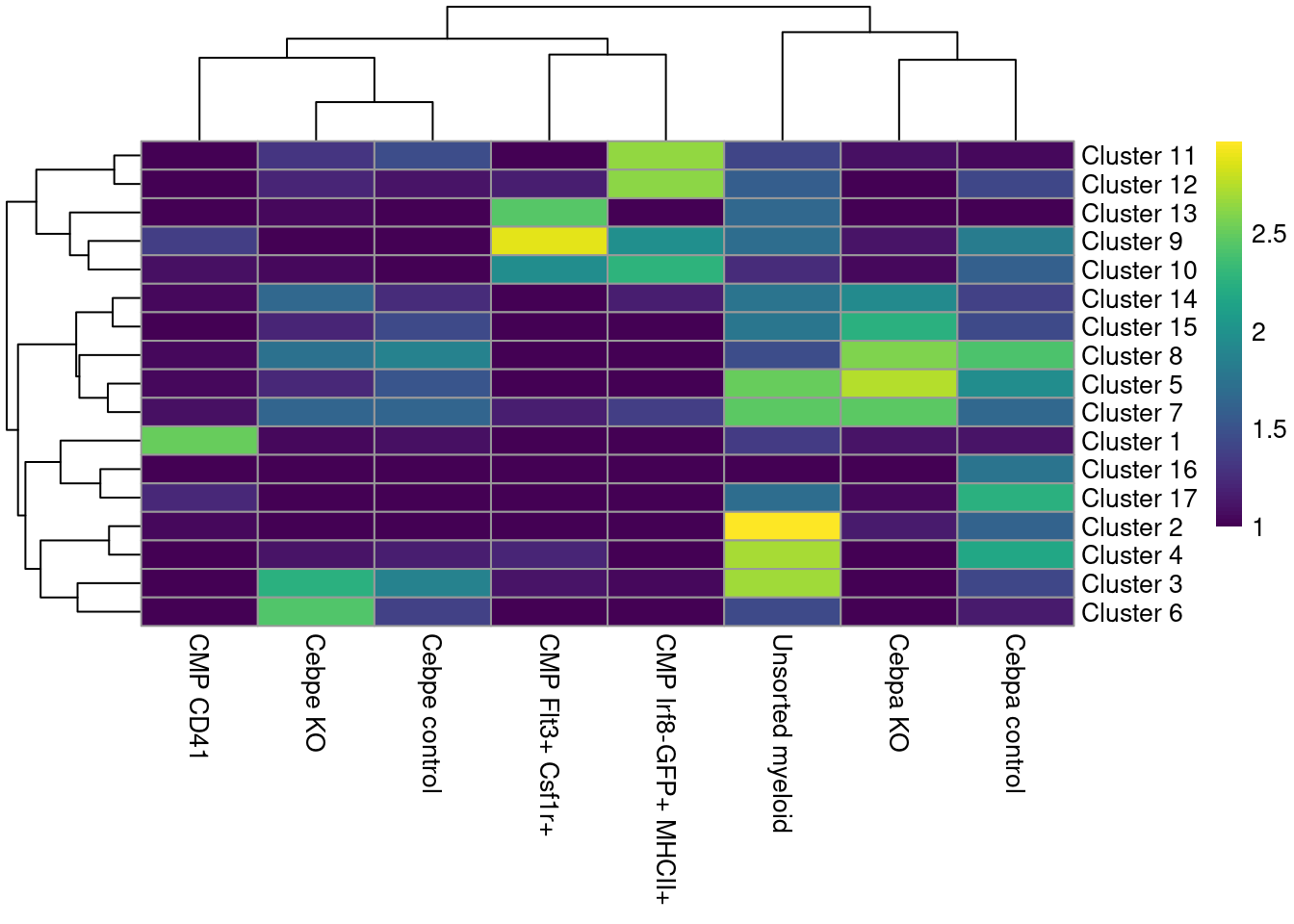
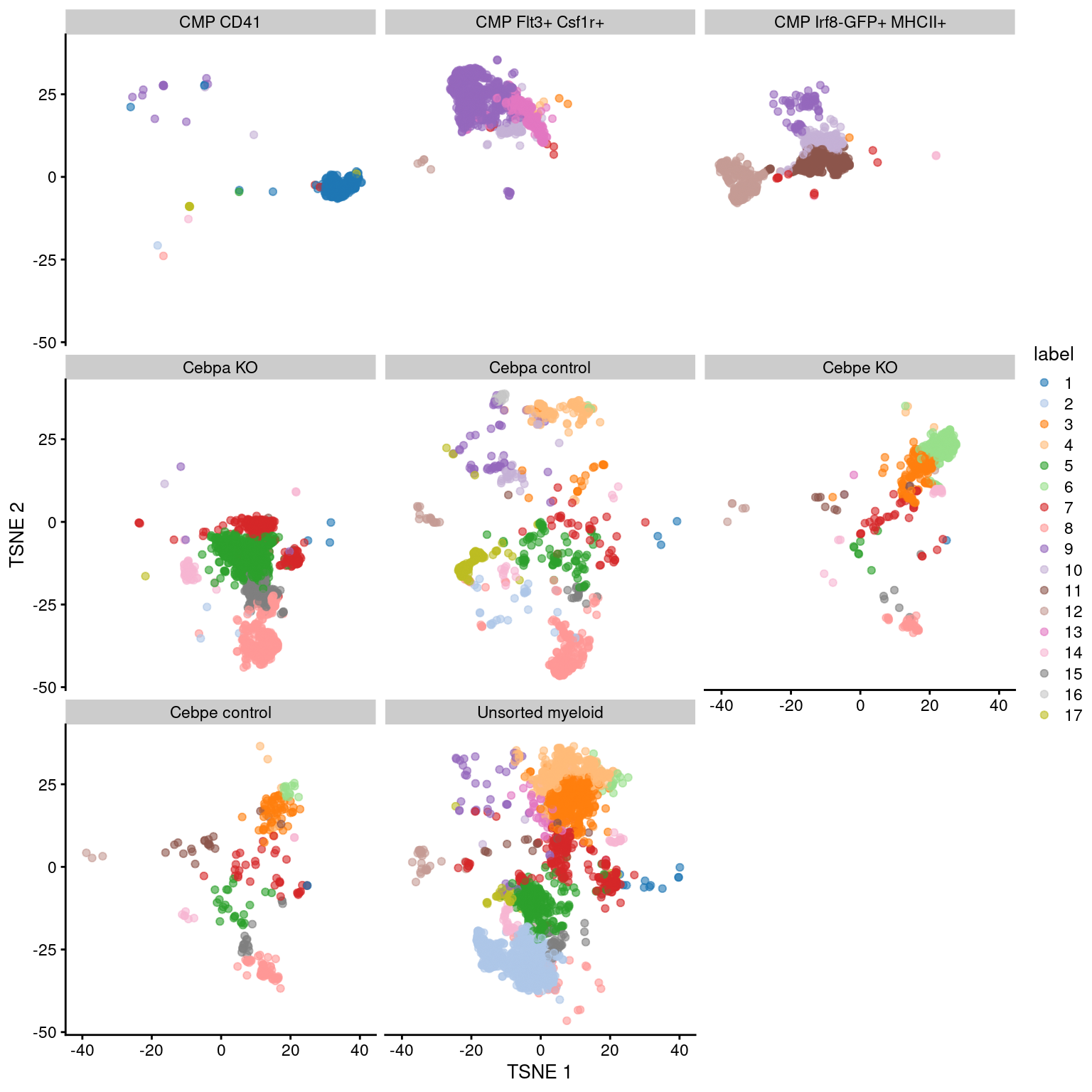
These is a strong relationship between the cluster and the experimental treatment (Figure \@ref(fig:unref-paul-heat)), which is to be expected.
Of course, this may also be attributable to some batch effect; the confounded nature of the experimental design makes it difficult to make any confident statements either way.
```r
tab <- table(colLabels(sce.paul), sce.paul$Batch_desc)
rownames(tab) <- paste("Cluster", rownames(tab))
pheatmap::pheatmap(log10(tab+10), color=viridis::viridis(100))
```
(\#fig:unref-paul-heat)Heatmap of the distribution of cells across clusters (rows) for each experimental treatment (column).
```r
plotTSNE(sce.paul, colour_by="label")
```
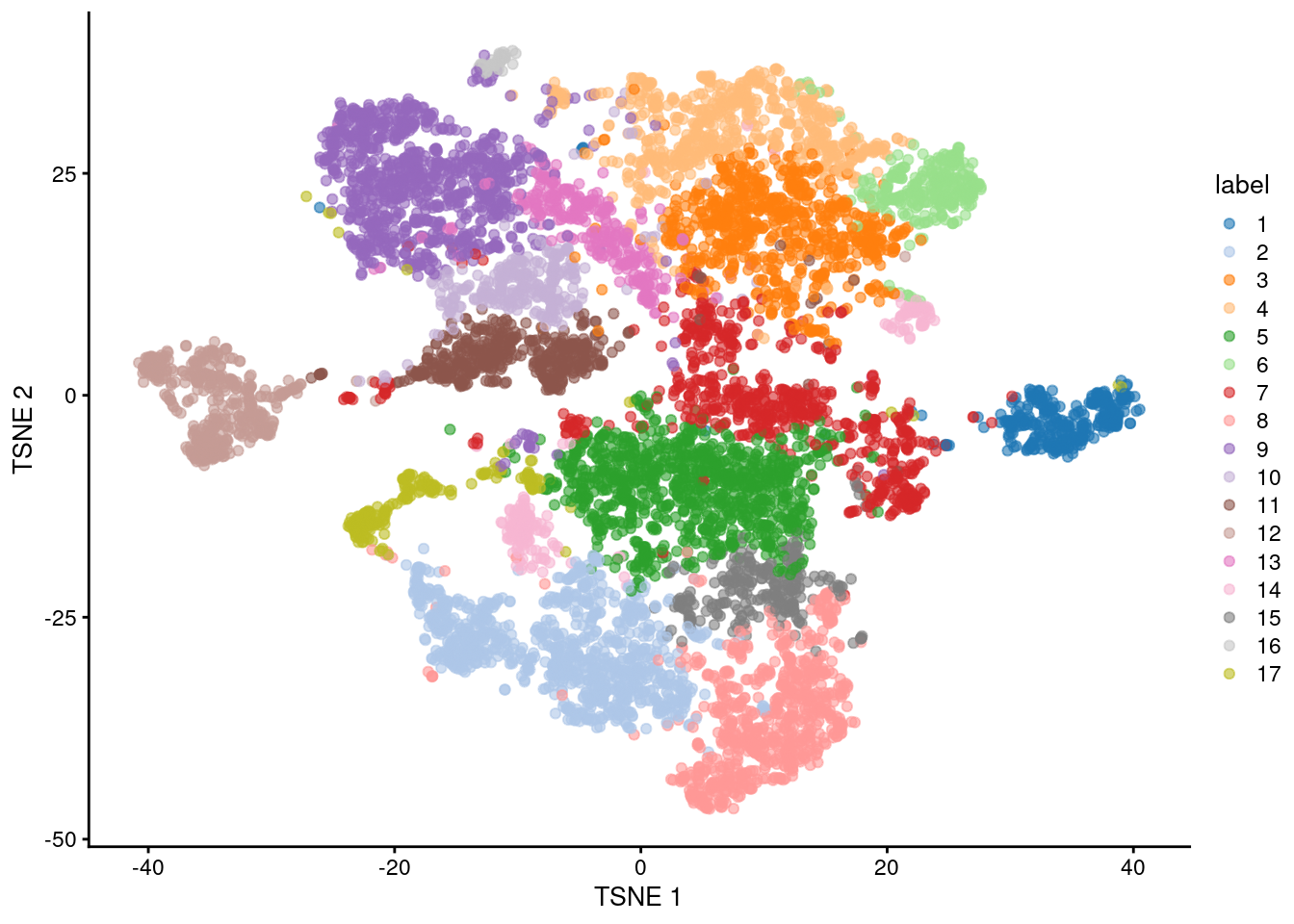
(\#fig:unref-paul-tsne)Obligatory $t$-SNE plot of the Paul HSC dataset, where each point represents a cell and is colored according to the assigned cluster.
(\#fig:unref-paul-tsne2)Obligatory $t$-SNE plot of the Paul HSC dataset faceted by the treatment condition, where each point represents a cell and is colored according to the assigned cluster.